








There's more than one way to...remove a file extension
This week I was working on a project that moves and archives file recordings and their accompanying XML meta data. I needed to remove the file extension from a file path stored as a string. The first thing I thought of was:
filename.Replace(".xml","")
That works, but it has to march through the whole string to the end to find what it needs to replace.
Substring seems more efficient:
filename.Substring(0, filename.Length - 4);
My Lead then reminded me that Path has a method for this very thing:
Path.GetFileNameWithoutExtension(filename)
At this point curiosity got the better of me. Which of these is actually more efficient? More importantly, which of these is more efficient for the strings I am working with? BenchmarkDotNet ftw! 🎉
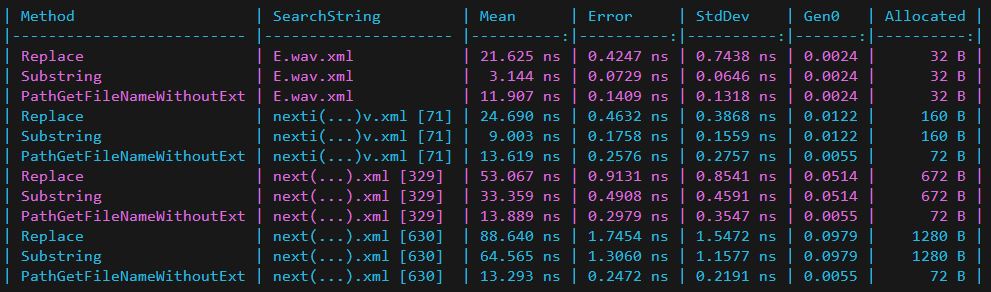 Fwiw, the strings I am working with are the 2nd result set with a length pretty close to 71.
Fwiw, the strings I am working with are the 2nd result set with a length pretty close to 71.
The fact that Replace was the worst performing isn’t a surprise, but there were a few surprises. I was surprised that the difference between Replace and Substring decreased as the size of the string got larger. Path.GetFileNameWithoutExtension had a couple of interesting finds. Once the string gets to a certain length the performance and allocated memory remains consistent no matter the length of the string. It also uses significantly less memory than the other two methods.
I looked at the Path.GetFileNameWithoutExtension and in short it:
- converts the path string to a
ReadOnlySpan<char> - gets just the filename from the path
- uses
LastIndexOf(".")to find the period before the extension - uses
Sliceto get the filename without the extension - converts the filename without the extension back to a string
I found this paragraph in an article exploring spans that gives an example of when you might want to use a span. It helps shed light on the benchmark results.
Or take another example. You’re implementing an operation over System.String, such as a specialized parsing method. You’d likely expose a method that takes a string and provide an implementation that operates on strings. But what if you wanted to support operating over a subset of that string? String.Substring could be used to carve out just the piece that’s interesting to them, but that’s a relatively expensive operation, involving a string allocation and memory copy. You could, as mentioned in the array example, take an offset and a count, but then what if the caller doesn’t have a string but instead has a char[]? Or what if the caller has a char*, like one they created with stackalloc to use some space on the stack, or as the result of a call to native code? How could you write your parsing method in a way that didn’t force the caller to do any allocations or copies, and yet worked equally well with inputs of type string, char[] and char*?
That was a fun diversion and an informative peek under the hood. Happy coding!





